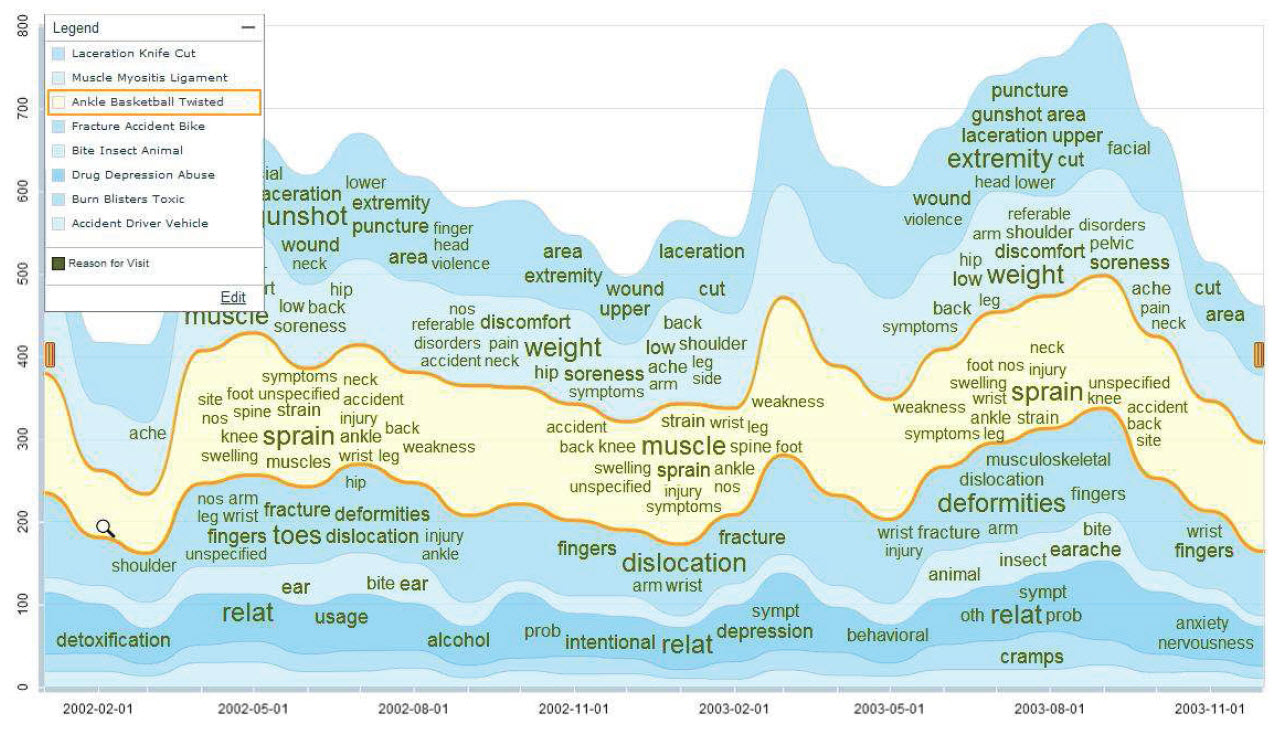
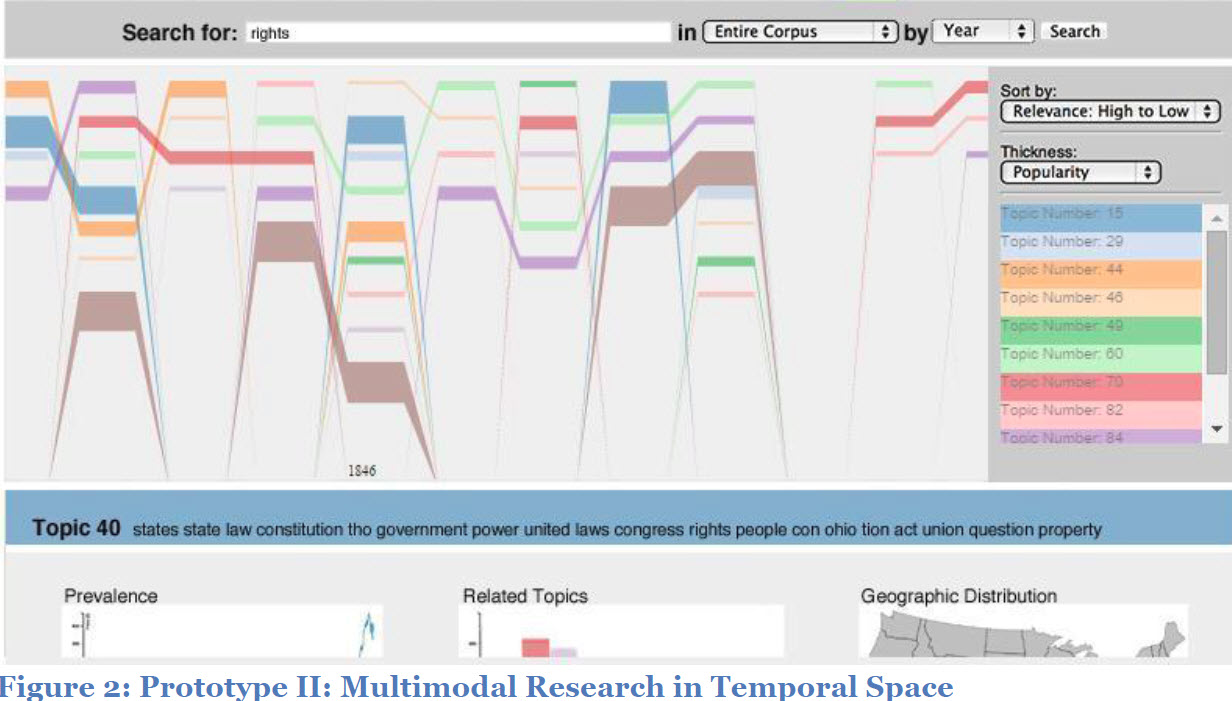
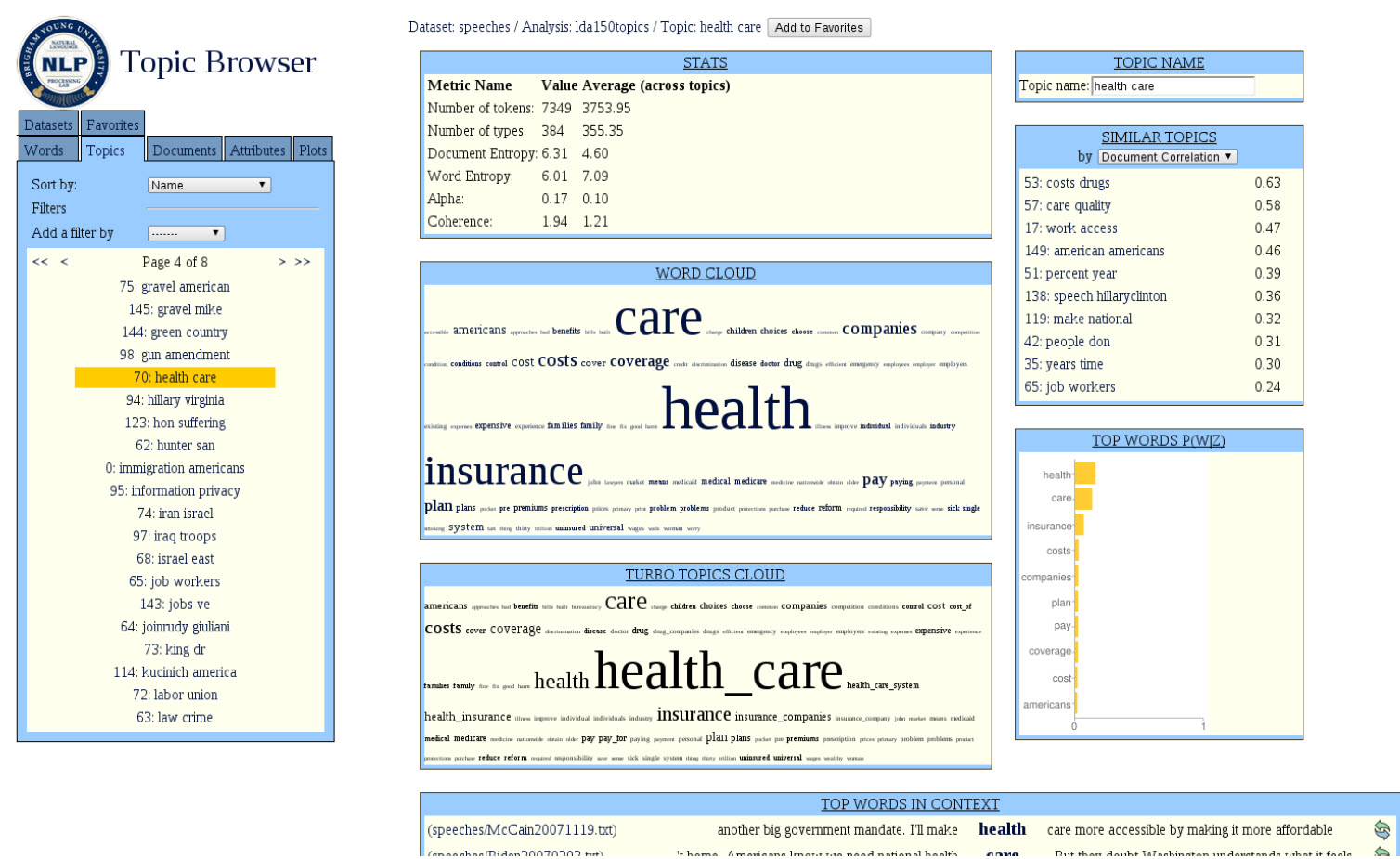
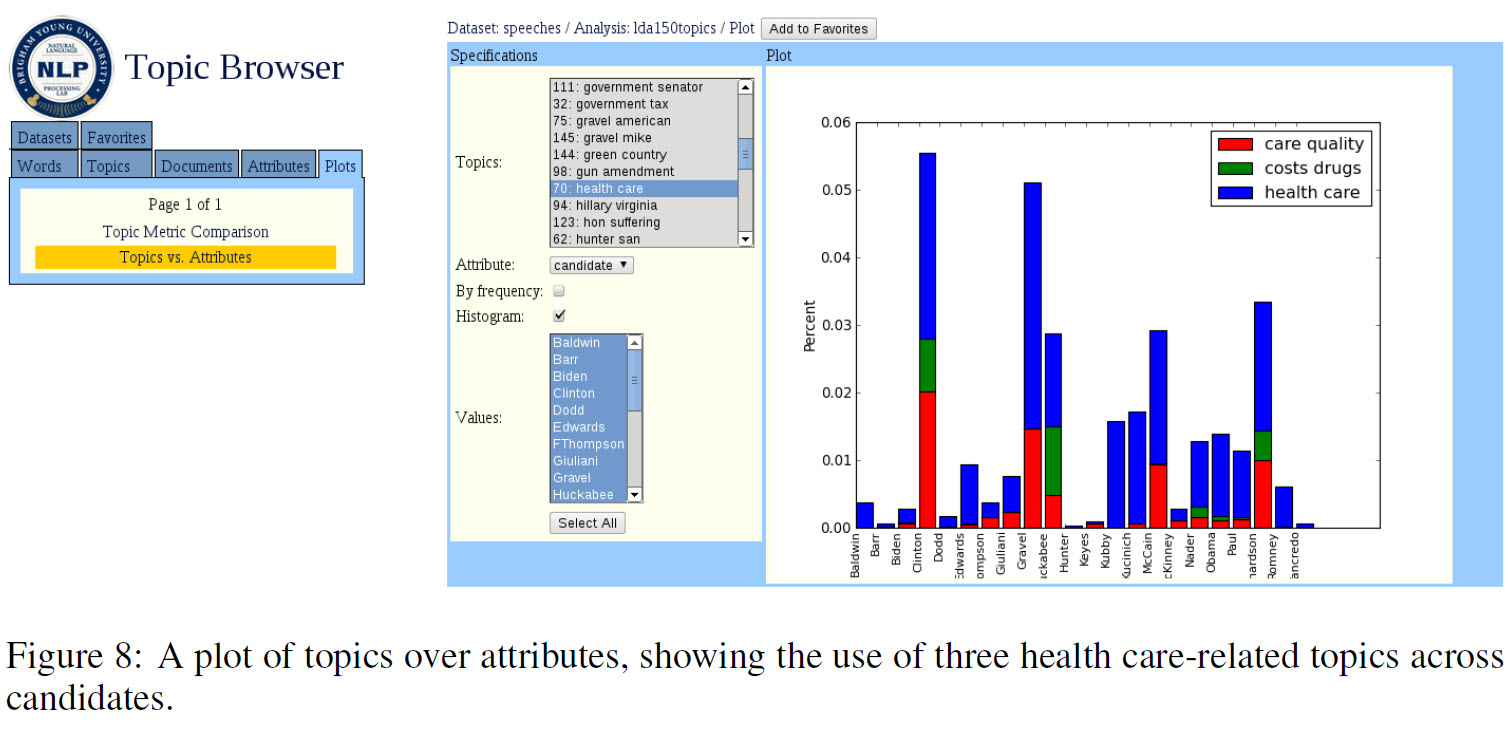
The Networked Corpus
Description: Jeff Binder and Collin Jennings, The Networked Corpus
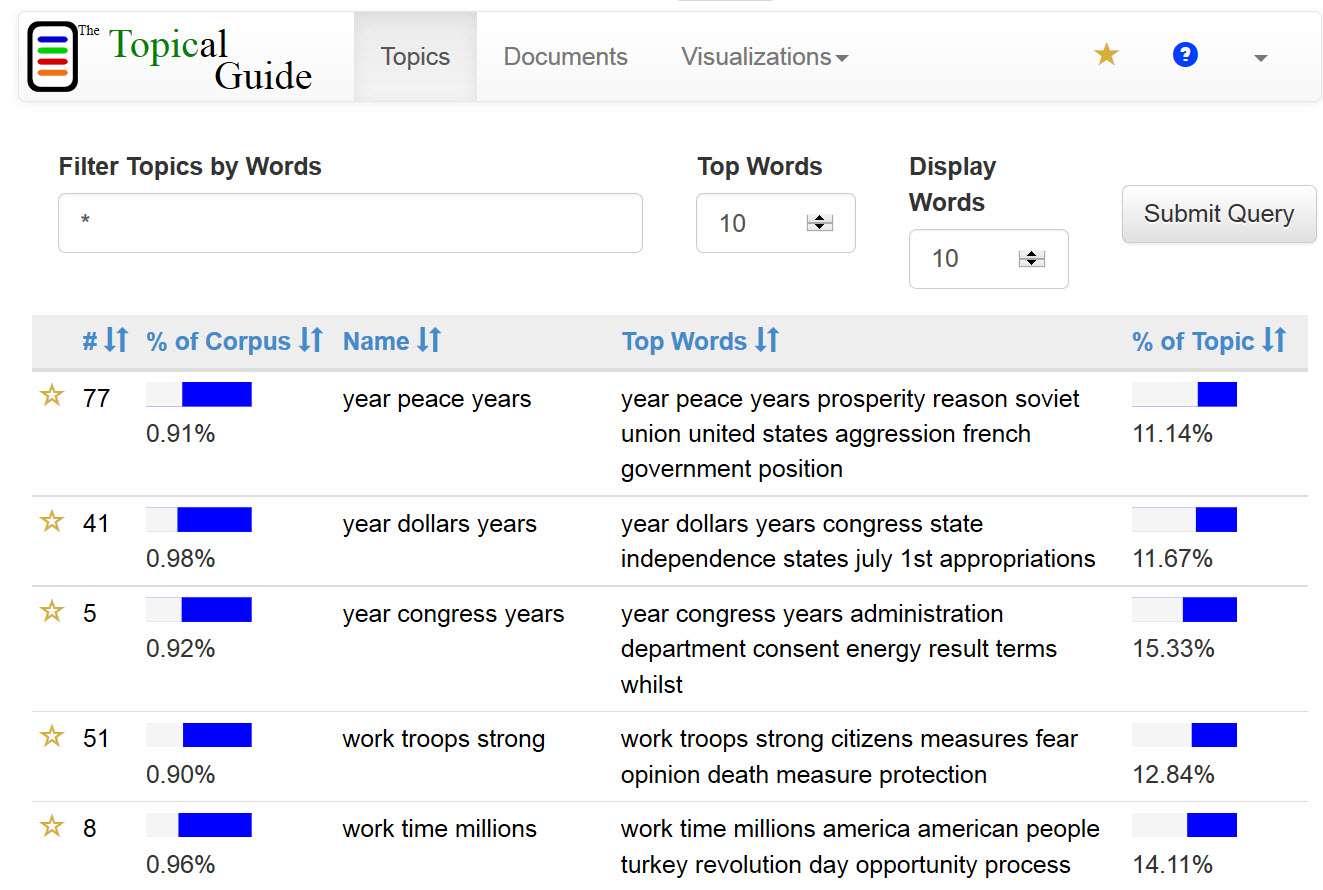
Topic modeling workflow:
Notable interpretive features of interface:
- Interactive visualization interface that takes input from Mallet. The key design principle of the interface is to avoid using topic labels (which can be deceptive) but instead to provide an easy way to identify passages in documents that are "dense" with a particular topic, allow them to be compared to other passages also dense with the topic, and thus provide the user with an understanding of a topic's meaning built up from intertextual context.
In particular, the interface:
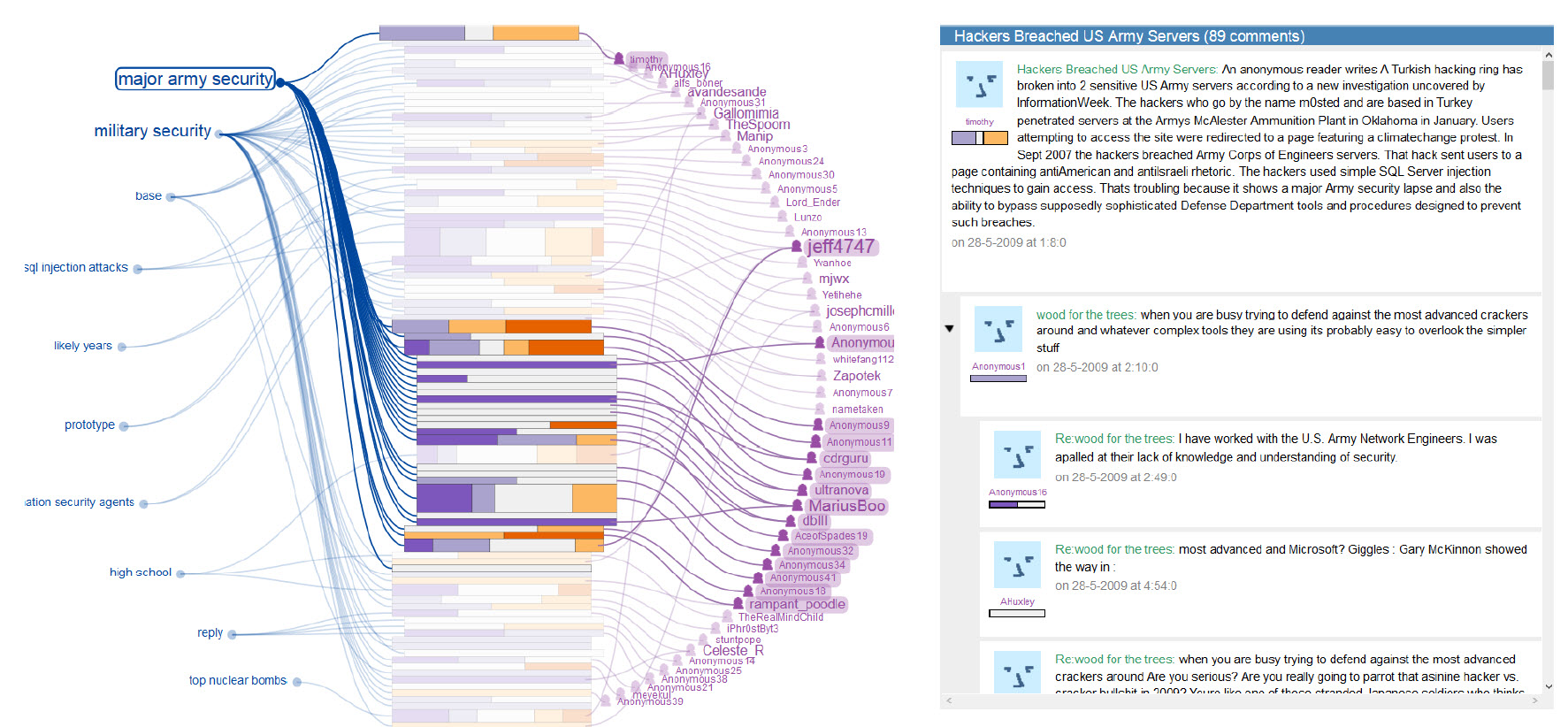
- Shows a document in the left panel; and shows a list of topics (by number) in the right panel
- Choosing a topic number highlights in the document the words that belong to that topic
- A line graphs the topic "density" of passages in the document, with peaks indicated with asterisk. Clicking on the asterisk calls up a list of links to other passages (including in other documents) that are dense with that topic.
(The density functions in the interface are calculated using Mallet's topic-state file as follows: "the density function is computed using kernel density estimation, which takes into account the words in nearby lines. Using these density functions, the program picks out ‘exemplary passages’ for each topic based on a simple rubric. Passages are only selected if the topic matches at least a certain number of words in the text (default 25), and they are only added if the topic’s maximum density in the text is at least (by default) four times as high as the average density of the whole document. If both of these conditions are met, an asterisk is created at the point of greatest density, with links to every other asterisk that was created for that topic.")
- Note: one interesting theoretical tenet of The Networked Corpus is that topic modeling produces an apparatus for understanding texts and moving around them non-linearly in a way analogous to earlier "indexing" (and other such apparatus) in the history of writing and print.
Code site: GitHub repo
Notes by WE1S team:
- Scott: Instructions for implementing The Networked Corpus.; includes adapted version of the code files as zip file; currently the instructions are for implementation on a Windows machine.
- Alan's step-by-step version of Scott's instructions, including a temporary kludge solution for non-ASCII character problems (arrived at after debugging correspondence with Scott below).
- Alan: This set of instructions gets The Networked Corpus to run. However, the results are not as expected and do not match the screenshots seen at the right. At first, my thought was that the browser.css and index.css files generated by the gen-networked-corpus.py script, together with the HTML in the html versions of each original text file also generated by that script, need to be tweaked for today's browsers. However, after investigation and experiments, that seems not to be the case.
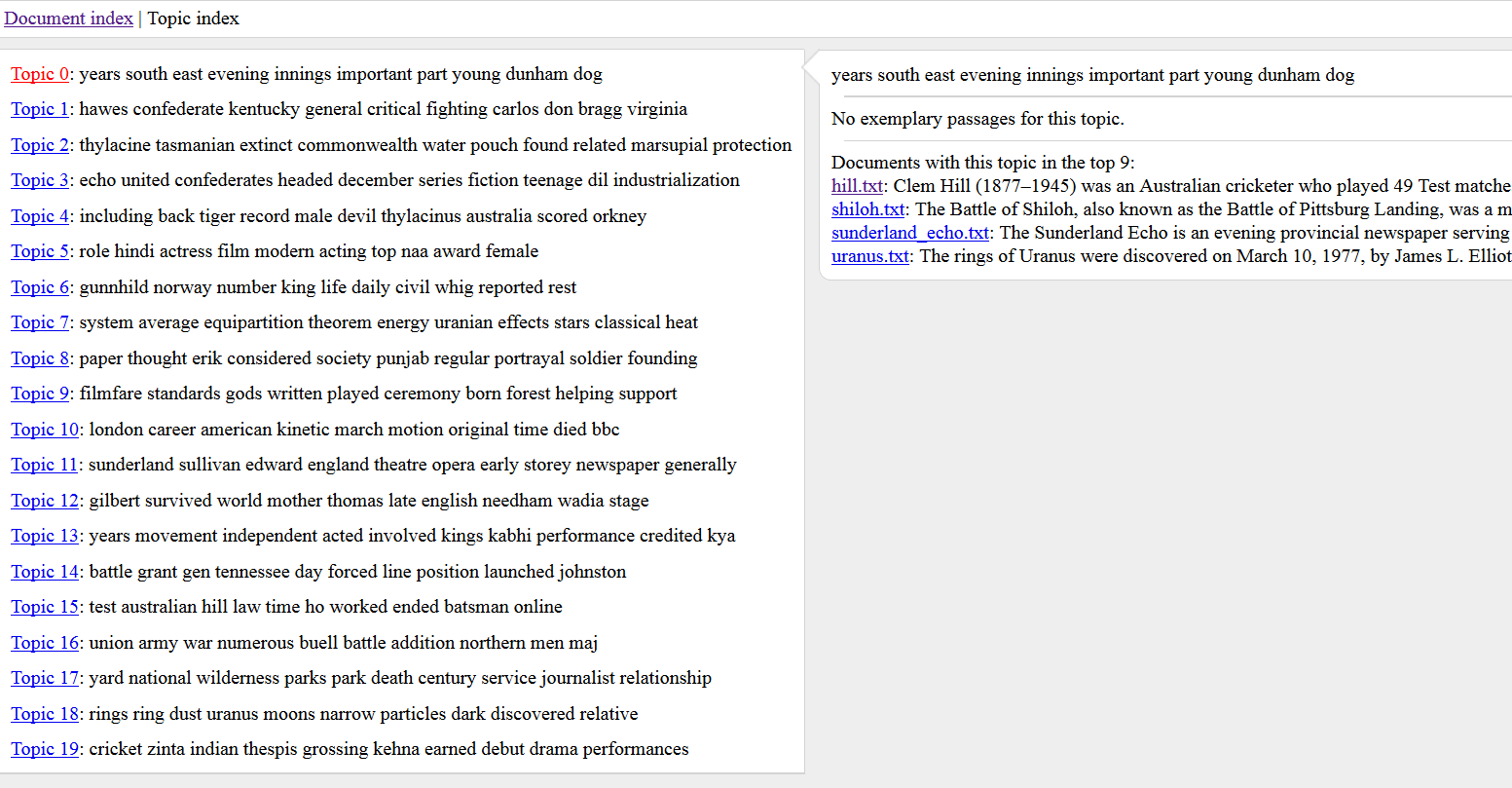
Instead, the problem seems to lie in a mismatch between our input text format and that expected by Networked Corpus. Here are the relevant instructions in the Networked Corpus Github site: "The text files must have hard line breaks at the end of each line. This is used to calculate how far down the page a word occurs, and also affects how wide the text will appear in the browser. If your source documents do not have line breaks and you are on a Mac or Linux system, you can use the 'fold' command to wrap them automatically. It doesn't matter whether the line breaks are Unix or DOS-style. Finally, the first line of each file should be a title; this will be used in the table of contents and in a few other places."
The plain-text article files in the WE1S corpus have no line breaks. Less important, they are not formatted in a way that makes the first line the title. (Instead, Networked Corpus ends up treating the entire text as a title, placing that in the title element in the head of each of the HTML file version it generates for an article.)
When using Mallet to create a topic model, the format of the original plain-text file and the presence or absence of line breaks is irrelevant. However, the way Networked Corpus seems to work is that it creates a HTML version of each original plain text file, which when opened in a browser is correlated via javascript scripts to the Mallet data about that file on a token-by-token basis. The format of the original plain-text files and the presence or absence of line breaks has an impact on these HTML files and they way they are displayed in a browser. In particular, Networked Corpus creates in the HTML page for an article a table of the text in which topic words for a chosen topic are highlighted. Each "line" of a text is supposed to be a single row, so that the table extends down the page row-by-row. But if the original plain-text file has no line breaks, then there is just a single row extending off the right of the page, nullifying the whole point of Networked Corpus's document view of the topic model.
It seem that the next step is to try the "fold" command referred to in the instructions from Networked Corpus's Github site above on the WE1S article files and see what we get.
- Debugging issues to date leading to above implementation solution:
- Alan's error report in response to Scott's initial instructions for implementing The Networked Corpus. Implementation produced the following error:
__init__.py", line 586, in <module>
from ._ufuncs import *
ImportError: DLL load failed: The specified module could not be found.
- Scott on the DLL load error: "I think the answer might be here. Try running "conda update scipy" from the command line."
- Alan's error report: "This worked. I'm finally getting gen-networked-corpus.py to run.
However, I'm now getting a unicode error:
File "C:\Users\Alan\Anaconda\lib\codecs.py", line 492, in read
newchars, decodedbytes = self.decode(data, self.errors)
UnicodeDecodeError: 'utf8' codec can't decode byte 0xac in position 0: invalid start byte
I created the .mallet file for the Mallet topic model using the regex parameter you
suggested: --token-regex "[\p{L}\p{M}]+"
I'm guessing this is the kind of error that caused you to start debugging the unicode problems in the first place. Let me know if you have any suggestions."
- Scott's response: "The line causing the Unicode error is part of a loop through a directory file list, so it seems to run into problems if the directory contains something other than the text files you are using to generate your topic model, This includes the Mallet output. When I set line 303 to a directory containing only the text files (in this case, one of your early New York Times collections), I didn't get the error.
Unfortunately, I got another error at the next stage, where the script was getting hung up at the name "François". Obviously, we can avoid this problem by striping diacritics,but we shouldn't have to. When I get a chance, I'll try to figure it out. But g ahead and try the advice in the previous paragraph, and see if it works for you."
- Alan's error report: "Thanks, Scott. I see. I was misunderstanding what the "datadir=" in line 303 is supposed to point to: the directory of original text files and not the directory of Mallet output files for the topic model of those text files.
Unfortunately, after getting that right I am getting another Unicode error that may be indicating an unexpected character in the plain text (just as you did):
File "C:\Users\Alan\Anaconda\lib\encodings\cp437.py", line 12, in encode
return codecs.charmap_encode(input,errors,encoding_map)
UnicodeEncodeError: 'charmap' codec can't encode character u'\u0301' in position 72: character maps to <undefined>
- Alan's temporary kludge solution to the above error: Use "search and replace" in Notepad++ (set to regex) to delete all non-ASCII characters in the article files being topic modeled for The Networked Corpus. (See instructions)
- (Scott's earlier notes: Some observations: The script must be run from within the input directory, and the script expects the Mallet output files to be named as shown in the sample command on GitHub. When I ran it, I encountered Unicode errors, so I tried a model using
--token-regex '[\p{L}\p{M}]+', as suggested on the GitHub repo. However, this caused the Mallet train-topics command to fail. Apparently, in Windows the regular expression must be enclosed in double quotes. The Python script also seems to have substantial problems with character encoding and/or Windows. I am hacking my way through it, gradually getting closer to a full implementation, but at the moment I'm stuck on a particularly confusing block of code. Update: I have never actually managed to get --token-regex to work in Mallet, so the point about double quotes is important independent of the Networked Corpus tool. As for the tool itself, I have finally managed to get it to run all the way through. I had to hack the code and inject my own paths to get it to pull data from the right folders. The result was a little disappointing, as it produced buggy html/css/javascript (or some combination of those). The following information is readable. Document Index, Topic Index, top 10 topics in each document, top 10 documents in each topic. The script is supposed to choose "exemplary passages" if the topic matches 25 words in the text and the topic's maximum density in the text is at least 4 times as high as the average over the whole document. There did not appear to be any "exemplary passages", perhaps because I used Mallet's tiny sample data set to build my model. Supposedly, if both of these conditions are met, an asterisk is created at the point of greatest density, with links to every other asterisk that was created for that topic. From the images displayed on the website, this appears to be a visualisation function using protovis.js. Either the javascript failed or it wasn't called simply because my data did not produce any exemplary passages.)
- Alan: Just to add information that may, or may not. be relevant to Scott's original problem with Unicode issues as documented in his note: the WE1S scraping workflow saves all plain-text files in UTF-8.
|



Click for a readable image
|